


Ansible is an open-source automation tool/configuration management tool that allows IT administrators and developers to automate the deployment, configuration, and management of software applications and infrastructure. It is designed to make complex tasks simpler by providing a simple, human-readable language that can be used to define and automate workflows.
Ansible uses a push-based model for configuration management, which means that it pushes out changes to remote systems rather than waiting for them to pull updates. This makes it easier to manage large and complex environments, as it reduces the likelihood of configuration drift and ensures that systems are always up-to-date.
One of the key advantages of Ansible is its simplicity. It uses YAML files to define tasks, which makes it easy for non-technical people to understand and modify playbooks. Additionally, Ansible does not require any agents or software to be installed on the target system, which makes it easy to deploy and use.
Configuration management can involve managing various types of configurations, including:
System configurations: This includes managing the configuration of operating systems, applications, and middleware, such as web servers, databases, and messaging systems. This can involve tasks such as installing, configuring, and maintaining software packages, configuring network settings, and managing system security settings.
Infrastructure configurations: This includes managing the configuration of infrastructure components, such as servers, storage systems, and network devices. This can involve tasks such as configuring IP addresses, managing network protocols, and configuring firewall rules.
Application configurations: This includes managing the configuration of applications, such as web applications, databases, and messaging systems. This can involve tasks such as configuring application settings, managing application security, and managing application data.
Security configurations: This includes managing the security configuration of IT systems, such as configuring firewall rules, managing user accounts and permissions, and implementing security policies.
PermalinkAdvantages :
Simple and easy to learn: Ansible uses a simple and easy-to-learn language for defining tasks, which makes it accessible to non-technical users.
Agentless: Ansible is an agentless tool, which means that it does not require any software to be installed on the target systems. This makes it easy to deploy and use.
Versatile: Ansible can be used for a wide range of tasks, including deployment, configuration management, and orchestration.
Efficient: Ansible uses a push-based model, which means that changes are pushed out to remote systems rather than waiting for them to pull updates. This reduces the likelihood of configuration drift and ensures that systems are always up-to-date.
Scalable: Ansible can manage large and complex environments, making it a scalable solution for IT professionals.
PermalinkDisadvantages:
Limited support for complex workflows: While Ansible can handle complex tasks, it may not be suitable for very complex workflows or environments.
The steep learning curve for advanced features: While the basics of Ansible are easy to learn, more advanced features can have a steeper learning curve.
Requires knowledge of Linux: Ansible is a command-line tool that requires a good understanding of Linux, which may not be accessible to all users.
Lack of graphical user interface: Ansible does not have a graphical user interface, which may make it less accessible to non-technical users.
PermalinkArchitecture of Ansible :
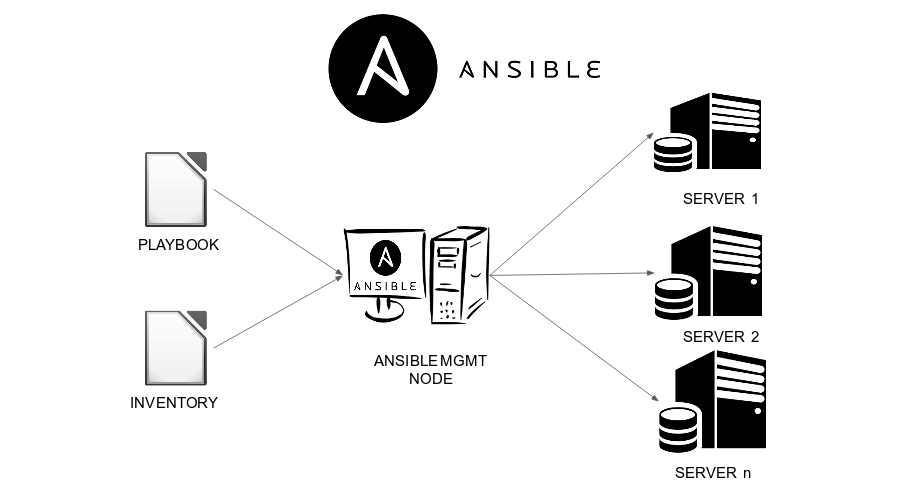
Control Machine: The control machine is where Ansible is installed and where playbooks and configuration files are stored. It is also where Ansible commands are run from, allowing you to manage and configure the managed nodes.
Managed Nodes: The managed nodes are the machines or devices that are being managed by Ansible. These can be servers, virtual machines, routers, or any other type of network-connected device that can be accessed via SSH or WinRM.
Ansible Modules: Ansible modules are small programs or scripts that perform specific tasks on the managed nodes, such as installing packages, configuring services, or copying files. Ansible modules can be built-in to Ansible or custom-developed by users to suit their specific needs.
PermalinkHere are some of the key terms and concepts used in Ansible:
Playbooks: Playbooks are YAML files that define the tasks and configurations that need to be applied to remote hosts.
Roles: Roles are a collection of tasks and configurations that can be reused across different playbooks.
Inventory: The inventory is a list of hosts and groups that Ansible manages. It can be defined in a static file or generated dynamically.
Modules: Modules are pre-written scripts that can be used to perform specific tasks on remote hosts. Ansible has a vast collection of built-in modules, and you can also create your own custom modules.
Tasks: Tasks are the actions that are executed on remote hosts, defined in playbooks.
Handlers: Handlers are like tasks, but they are only executed when a specific condition is met, such as when a service needs to be restarted.
Variables: Variables are used to store and reuse values in playbooks, such as the name of a package to install or the IP address of a remote host.
Templates: Templates are used to generate files dynamically based on variables and configurations defined in playbooks.
Facts: Facts are information about the remote host, such as the operating system version, hostname, and IP address. Ansible gathers these facts automatically and stores them in memory.
Vaults: Vaults are used to encrypt sensitive data, such as passwords or API keys, in playbooks and templates.
Playbook Control: The playbook control mechanism of Ansible enables you to conditionally control the execution of tasks within a playbook.
Callback Plugins: Callback plugins are used to customize the output generated by Ansible when running playbooks.
Ansible Galaxy: Ansible Galaxy is a public repository of Ansible roles, collections, and modules that are contributed by the community.
PermalinkHow ansible execute your playbook?
When you run an Ansible playbook, Ansible will execute the tasks defined in the playbook on the managed nodes in a specific order. Here's a high-level overview of how Ansible executes a playbook:
Ansible connects to the managed nodes using SSH or WinRM, depending on the platform.
Ansible gathers information about the managed nodes using modules, which are small scripts that run on the managed nodes to collect information or perform tasks. This information includes the operating system, network configuration, installed packages, and other system information.
Ansible evaluates the hosts and groups specified in the playbook and determines which tasks to execute on which hosts.
Ansible executes the tasks defined in the playbook on the managed nodes in the order specified in the playbook. Tasks can include things like installing packages, copying files, and running scripts.
Ansible applies any conditionals or loops specified in the playbook to control the flow of the execution.
Ansible can also use handlers, which are tasks that are only executed if another task notifies them. Handlers are typically used to restart services or reload configurations after changes have been made.
Ansible logs the output of the tasks and provides a summary of the changes made on the managed nodes.
Ansible disconnects from the managed nodes and returns control to the user.
This is a simplified overview of how Ansible executes a playbook, but it should give you an idea of the general process. Ansible provides a lot of flexibility and control over how playbooks are executed and can be customized to meet the needs of your specific environment.
PermalinkAnsible Ad hoc
Ansible Ad hoc is a command-line interface (CLI) tool that allows you to run Ansible commands quickly and easily, without the need to write playbooks or create inventories. With Ansible Ad hoc, you can perform one-off tasks or execute commands on one or more managed nodes, without having to create complex configurations.
Ad hoc commands are executed from the command line on the Ansible control machine and are sent to the managed nodes using SSH or WinRM. Ad hoc commands are typically used for simple tasks, such as checking the status of a service, gathering system information, or restarting a service. They can also be used for troubleshooting or testing purposes, or for performing one-time tasks that don't require a full playbook.
To use Ansible Ad hoc, you simply specify the command and the target hosts or groups, and Ansible will execute the command on the specified hosts or groups. Ad hoc commands can also be combined with Ansible modules to perform more complex tasks or configurations.
For example, the following command uses the ping module to check the connectivity of all hosts in the "web" group:
ansible web -m ping
This command will send the ping module to all hosts in the "web" group and return the results of the ping test.
PermalinkAnsible Playbook
An Ansible playbook is a YAML file that defines a set of tasks and configurations to be executed on one or more managed nodes. Playbooks allow you to automate complex tasks, configurations, and deployments by specifying a series of steps to be executed in a particular order. Playbooks can include tasks such as installing packages, configuring services, copying files, and running scripts, and can also include conditionals, loops, and handlers.
A playbook is composed of one or more plays, which are logical groupings of tasks that target a specific set of hosts or groups. Each play specifies the hosts or groups to target and then defines a set of tasks to be executed on those hosts or groups.
Playbooks are executed from the command line on the Ansible control machine using the ansible-playbook command. This command reads the playbook file and sends the required tasks and configurations to the managed nodes using SSH or WinRM. Playbooks can be run in parallel across multiple hosts, making it easy to manage large numbers of machines or devices.
For example, the following is a simple Ansible playbook that installs the Apache web server on a group of servers:
---
- name: Install Apache
hosts: webservers
become: true
tasks:
- name: Install Apache
yum:
name: httpd
state: present
This playbook defines one play, which targets the group "webservers". It then includes one task, which installs the Apache web server on those servers using the yum module. When this playbook is executed, it will install Apache on all hosts in the "webservers" group.
PermalinkWhat is role and how its dir structure looks like?
In Ansible, a role is a collection of tasks, files, templates, variables, and other components that are grouped together and organized in a specific directory structure. A role is designed to be reusable and can be easily shared across different projects or organizations.
Roles are used to organize and encapsulate the configuration and management of a particular component or aspect of a system, such as a web server, database server, or monitoring tool. They allow you to define the configuration of an entire component in a single place, making it easy to manage and maintain over time.
Roles follow a specific directory structure and typically include a tasks directory, which contains the main tasks for the role, as well as other directories for files, templates, variables, defaults, and meta information. By following this directory structure, roles can be easily shared and reused, and can be easily understood and maintained by other users.
web
├── defaults
│ └── main.yml
├── files
├── handlers
│ └── main.yml
├── meta
│ └── main.yml
├── README.md
├── tasks
│ └── main.yml
├── templates
├── tests
│ ├── inventory
│ └── test.yml
└── vars
└── main.yml
tasks/: This directory contains the main tasks file for the role. It typically includes one or more YAML files that define the tasks to be executed on the managed nodes.handlers/: This directory contains the handler tasks for the role. Handlers are tasks that are only executed if a notification is received from another task. Handlers are typically used to restart services or reload configurations after changes have been made.files/: This directory contains files that need to be copied to the managed nodes. These files are usually static files, such as configuration files or scripts.templates/: This directory contains Jinja2 templates that are used to generate configuration files or scripts that are copied to the managed nodes.vars/: This directory contains variables that are specific to the role. These variables can be used in tasks and templates, and can be overridden by variables defined in other directories or in the playbook.defaults/: This directory contains default variables for the role. These variables are used if no other variables are defined, and can be overridden by variables defined in other directories or in the playbook.meta/: This directory contains metadata about the role, such as its dependencies, author, and description.